
AI Startup Infrastructure: From LLM MVP to Platform Problem
Most AI startups begin the same way: there is an idea, an LLM API, a fast prototype, and a few early users. At this stage, infrastructure feels secondary. The real goal is to prove the product, validate the workflow, and avoid spending months building engineering systems that may never matter.
That is the correct approach.
The problem starts later.
The prototype works. Users come back. The team adds RAG, background jobs, integrations, agents, file processing, vector search, billing, quotas, logs, deployment automation, and monitoring. Then the first enterprise customers arrive and start asking about data isolation, audit logs, private deployment, SSO, SLAs, security boundaries, and cost controls.
At that point, the AI product is no longer just an application that calls an LLM API. It has become a platform.
And if the infrastructure was not designed to evolve, growth starts breaking the product.
This article is a practical map of how AI startup infrastructure evolves from a simple LLM prototype to a production-grade AI platform. It is not a generic list of fashionable tools. It is a maturity path for real AI products as they move from MVP to enterprise readiness.
If your AI product has already reached the stage where infrastructure affects reliability, margin, security, or enterprise sales, this is where AI platform engineering starts to matter.
Why AI Infrastructure Is Different From Traditional SaaS Infrastructure
A traditional SaaS product has to scale backend services, databases, queues, caches, APIs, deployments, and monitoring. That is already hard, but the failure modes are usually familiar.
An AI product adds a new layer of complexity.
Now the system must manage not only user requests, but also model behavior. It must track not only backend logs, but prompts, context, retrieved documents, embeddings, tool calls, model versions, token usage, latency, and answer quality.
In traditional SaaS, a failure may look like an API returning a 500 error or a database struggling under load.
In an AI product, failure can look very different. The model gives a confident but wrong answer. RAG retrieves an outdated document. An agent calls the wrong tool. A single workflow costs more than the revenue from that user. An enterprise deal stalls because the product does not support tenant isolation.
That is why AI infrastructure is not just DevOps. It sits at the intersection of backend engineering, data engineering, platform engineering, security, observability, cost control, and product quality.
The broader market is moving in the same direction. Bessemer describes AI infrastructure as a new infrastructure layer covering model deployment, data operations, observability, orchestration, and application infrastructure: Bessemer: The Roadmap for AI Infrastructure. a16z made a similar point with its early reference architecture for LLM applications, showing that production LLM systems quickly become a stack of data pipelines, retrieval, orchestration, logging, and model interfaces: a16z: Emerging Architectures for LLM Applications.
For startups, the important lesson is simple: AI infrastructure is not a fixed stack. It is a maturity path.
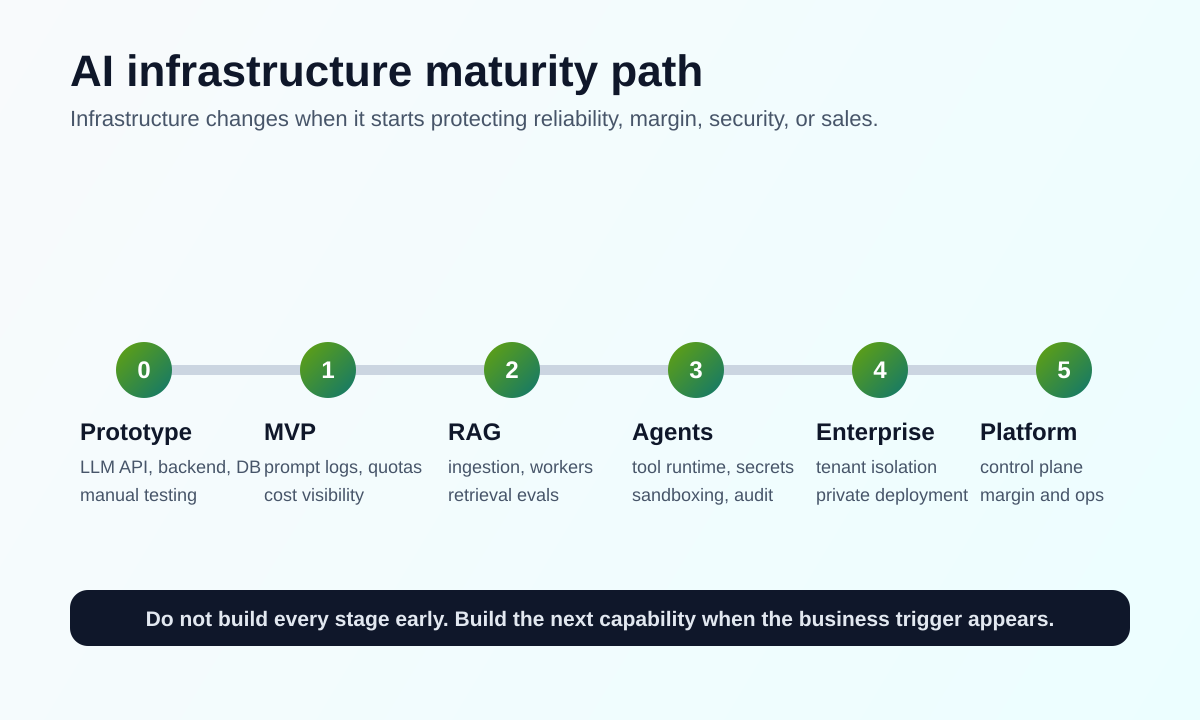
Stage 0: Prototype Infrastructure
At the prototype stage, the goal is to prove product value.
A simple stack is usually enough: an LLM API, a backend application, a database, a minimal UI, a few prompt templates, basic logs, and manual testing.
At this stage, you should not prematurely build a Kubernetes platform, self-hosted inference, a complex agent framework, or a full observability stack. That adds operational complexity before the team knows whether the product is worth scaling.
A good AI prototype is fast, cheap, and easy to change.
A bad AI prototype tries to look like an enterprise platform before there are enterprise customers.
The main rule at this stage is straightforward: infrastructure should help the team validate product hypotheses, not demonstrate engineering maturity.
Stage 1: MVP With Real Users
Once real users start using the product, problems appear that did not exist in the demo.
Users ask unexpected questions. Requests become longer. LLM API costs increase. Model answers become inconsistent. The team cannot always explain why the product produced a specific result.
At this stage, the product needs basic AI infrastructure capabilities:
- Prompt and response logging
- Token usage tracking by user, workspace, feature, or workflow
- User-level quotas and limits
- Timeout and retry handling
- Basic error monitoring
- Prompt template versioning
- Request history
- A minimal cost dashboard
This is not a full AI platform yet, but it is the beginning of platform thinking.
If the team cannot see how much each user costs, which prompts fail most often, where latency spikes happen, or why the model produced a bad answer, the product becomes difficult to improve.
The goal is not to overbuild. But the team can no longer remain blind.
Stage 2: RAG Becomes Product Infrastructure
Many AI startups add RAG as a fast way to improve model answers. They upload documents, split them into chunks, create embeddings, store them in a vector database, retrieve similar passages, and pass them into a prompt.
That may be enough for a demo.
It is not enough for production.
When RAG becomes part of a real product, it becomes a data platform inside the product.
Now the team must think about ingestion quality, document freshness, access control, tenant isolation, chunking strategy, hybrid search, reranking, citations, deduplication, and retrieval evaluation.
The most common mistake is treating RAG as if it were just a vector database.
The vector database is only one component. Production RAG requires much more:
- Reliable data ingestion pipelines
- Queues and background workers
- Error handling for parsing and indexing
- Re-indexing and refresh paths
- Document-level access control
- Tenant-aware retrieval
- Retrieval quality metrics
- Debugging tools for retrieved context
- Protection against outdated or irrelevant data
If RAG performs poorly, users do not always see a technical error. They simply get a weak answer and lose trust in the product.
That means RAG infrastructure directly affects retention.
This is one of the core areas where ToolLeap works with AI startups: turning fragile RAG flows into production-grade pipelines with ingestion observability, permissions, refresh logic, queues, workers, and retrieval quality controls. See ToolLeap AI Platform Engineering for the broader platform context.
Evaluation also becomes important here. OpenAI describes evals as task-specific tests used to measure the behavior and quality of AI systems, not just generic benchmark scores: OpenAI: Evaluation Best Practices. For a RAG product, that means measuring whether the system retrieves the right information, grounds answers correctly, and avoids regressions when prompts, embeddings, or ranking logic change.
Stage 3: Agents Change the Risk Model
The next stage begins when AI does not just answer. It acts.
An agent may call an API, run a workflow, modify data, send a message, execute code, open a pull request, generate deployment configuration, or interact with a customer's internal systems.
At that point, infrastructure becomes a security problem.
If a model only writes text, a mistake is unpleasant. If a model performs actions, a mistake can be expensive.
Agent-based products need a controlled execution layer.
That means:
- Tool runtime
- Execution isolation
- Secrets management
- Audit logs
- Rate limits
- Approval flows
- Sandboxing
- Network restrictions
- Human-in-the-loop controls for risky actions
- Replay and debugging mechanisms
- Tenant, user, and role-based execution boundaries
You cannot simply give an agent direct access to production APIs or customer environments.
This is especially important when the product works with customer-owned code, CI runners, deployment pipelines, cloud credentials, private networks, or internal tools.
At this stage, the AI startup is no longer building only an application. It is building an execution platform.
The market is already validating this direction. AWS Bedrock AgentCore separates production agent capabilities such as runtime, memory, gateway, identity, code execution, browser automation, observability, evaluations, policy, and registry: AWS Bedrock AgentCore Documentation. Microsoft also frames enterprise agent systems around control plane capabilities such as inventory, observability, compliance, security, and cost tracking: Microsoft Foundry Control Plane.
For startups, the lesson is direct: once AI can act, infrastructure must enforce boundaries.
Stage 4: Enterprise Customers Change the Infrastructure Roadmap
When a product is sold to small teams, many infrastructure gaps can be handled manually.
Enterprise customers change the conversation.
They ask not only what the product does, but also:
- Where is the data stored?
- Can the product run in a private environment?
- Does it support SSO or SAML?
- How are tenants isolated?
- Can we export audit logs?
- What SLAs are available?
- How is agent access to tools controlled?
- Can the product run on customer-owned infrastructure?
- Can data be restricted to a specific region?
- How is data deleted?
- How are model usage and token costs tracked?
At this stage, infrastructure becomes a sales feature.
If the architecture cannot support enterprise requirements, a deal may stall not because the product is weak, but because the platform is not ready.
This is especially important for AI startups working with code, documents, internal knowledge bases, customer data, cloud environments, or automation workflows.
Enterprise AI almost always requires stronger isolation, observability, and control.
Stage 5: The Platform Becomes the Product
At the mature stage, infrastructure stops being an internal technical concern. It starts directly affecting the business.
Inference cost affects gross margin.
Latency affects conversion.
RAG quality affects retention.
Agent safety affects enterprise sales.
Tenant isolation affects customer size.
Observability affects support and trust.
Private deployment affects the ability to close larger deals.
CI runner isolation affects whether the product can safely work with customer-owned code.
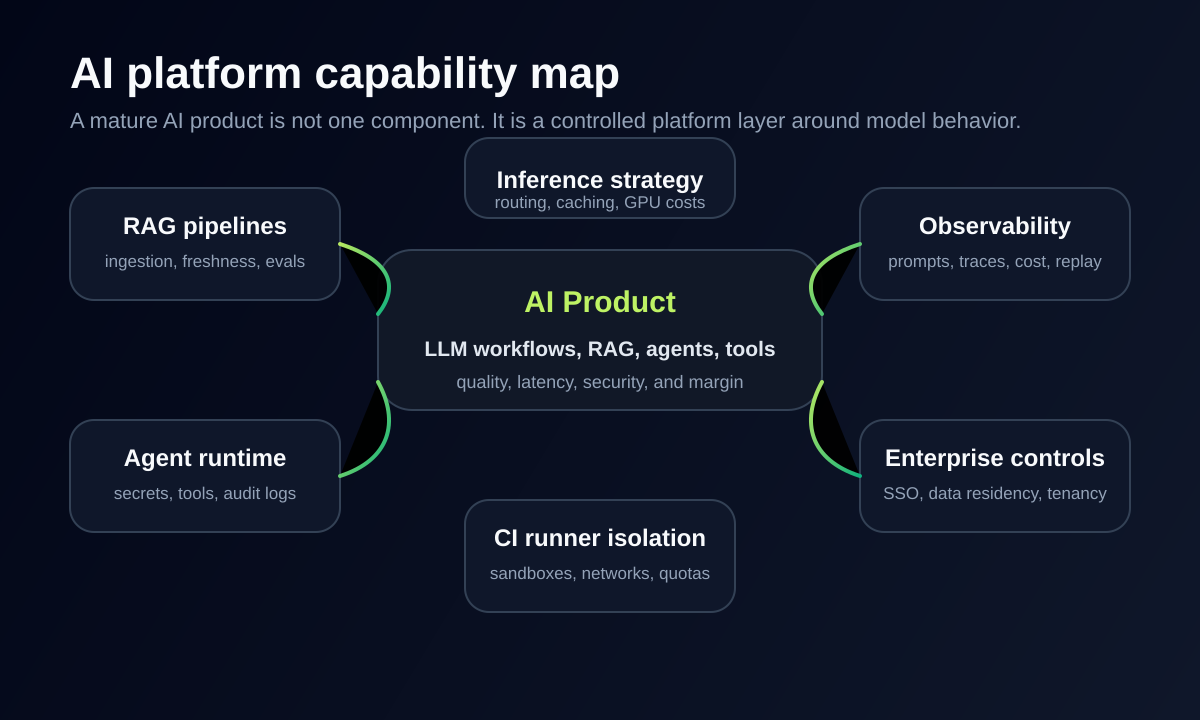
This is the point where the startup no longer needs only backend maintenance. It needs AI platform engineering.
AI platform engineering is the work of turning a working AI product into a reliable, scalable, secure, and operable platform.
It includes RAG pipelines, agent tool runtime, Kubernetes deployments, private environments, observability, cost control, GPU inference strategy, CI runner isolation, security boundaries, and a control plane for managing these systems.
At this point, infrastructure is not overhead. It is a competitive advantage.
Build, Buy, or Defer: A Practical Decision Framework
A common mistake is assuming every AI startup needs the same infrastructure stack.
It does not.
At the early stage, managed services are usually the right choice. They let the team move quickly without spending engineering time on infrastructure that has not yet proven its value.
Build internally only when the capability directly affects differentiation, margin, security, latency, enterprise readiness, or product quality.
Defer anything that looks mature but does not help the team acquire users, reduce risk, improve reliability, or increase revenue.
For example, you do not need self-hosted inference just because it sounds serious. But if inference cost is destroying margin or latency is damaging the user experience, then model routing, caching, batching, or GPU strategy become business problems.
You do not need a complex agent platform before you have repeatable agent workflows. But if agents already perform actions in customer environments, sandboxing and audit logs cannot be postponed.
You do not need Kubernetes for a simple MVP. But if the product requires private deployments, workload isolation, predictable rollouts, and enterprise-grade operations, Kubernetes may become the right foundation.
A good infrastructure strategy is not about building everything.
It is about knowing what to build now, what to buy, and what to deliberately avoid.
Reference Architecture by Maturity Stage
| Stage | Product state | Infrastructure needed | What to avoid |
|---|---|---|---|
| Prototype | Demo or design partners | LLM API, simple backend, database, basic logs, manual testing | Kubernetes, self-hosted GPUs, complex orchestration |
| MVP | First real users | Prompt logs, token tracking, retries, quotas, basic monitoring, request history | A heavy platform before product-market signal |
| RAG product | Knowledge quality matters | Ingestion pipelines, queues, workers, vector or hybrid search, access control, retrieval debugging, evals | Treating RAG as one script or one vector DB |
| Agent product | AI takes actions | Tool runtime, secrets management, sandboxing, audit logs, approval flows, execution boundaries | Direct tool access without isolation |
| Enterprise | Larger customers and security reviews | Tenant isolation, private deployment options, SSO, audit exports, SLAs, data residency | One shared tenant architecture with manual exceptions |
| Platform | Infrastructure affects revenue | Control plane, platform layer, observability, cost governance, inference strategy, CI runner isolation, release process | Ad hoc DevOps and one-off customer deployments |
Common Mistakes AI Startups Make
The first mistake is building a platform too early.
The team spends months on infrastructure before proving that the product is needed by the market.
The second mistake is building a platform too late.
The MVP starts growing, larger customers appear, and the architecture cannot support isolation, security, observability, or predictable deployments.
The third mistake is treating RAG as a simple integration.
Without ingestion quality, permissions, freshness, and retrieval evals, RAG quickly becomes a source of user distrust.
The fourth mistake is giving agents too much access.
An agent without sandboxing, audit logs, and permissions is not just a feature. It is an infrastructure risk.
The fifth mistake is not measuring cost at the user, workspace, or workflow level.
An AI product can look successful by usage while being unprofitable by unit economics.
The sixth mistake is not having replay and debugging mechanisms.
If the team cannot reconstruct which prompt, context, model version, and tools were used in a specific request, support and product iteration become slow.
The seventh mistake is promising enterprise capabilities before the architecture is ready.
That creates custom deployments, manual workarounds, unstable integrations, and technical debt that becomes difficult to remove later.
How to Know You Need AI Platform Engineering
There are several clear signals.
You cannot explain the cost of one AI workflow.
You cannot quickly debug a bad model answer.
Your RAG system depends on fragile scripts and manual re-indexing.
Agents can access tools without strong execution boundaries.
Enterprise customers ask about security, isolation, and private deployment, and the team does not have a clear architecture answer.
Support cannot reconstruct which prompt, context, and model version were used in a specific request.
Deploying AI components has become risky.
The team is afraid to change prompts, retrieval logic, or agent tools because there are no evals or regression checks.
If several of these are true, the problem is no longer “one more DevOps task.” The product has grown into a platform problem.
Conclusion
An AI startup does not need complex infrastructure on day one.
But it does need the right infrastructure at the right time.
At the beginning, speed matters. At the MVP stage, visibility into model behavior and cost matters. With RAG, data quality and retrieval quality matter. With agents, safe execution matters. With enterprise customers, isolation, auditability, and private deployment matter. At the platform stage, control plane, observability, cost governance, and production operations matter.
The goal is not to build the most complex stack.
The goal is to prevent infrastructure from becoming the constraint on growth.
If your AI product has moved beyond MVP and infrastructure is starting to affect reliability, margin, security, or enterprise sales, this is no longer a generic backend problem.
It is AI platform engineering.
ToolLeap helps AI startups make that transition: from a working LLM product to a production-grade AI platform with RAG, agents, CI runner isolation, Kubernetes, observability, GPU inference, and private deployments.
Get an AI Infrastructure Maturity Audit
If your AI product is moving beyond MVP and infrastructure is starting to affect reliability, margin, security, or enterprise sales, ToolLeap can help you map the next platform stage.
We review your RAG pipelines, agent tool runtime, CI runner isolation, Kubernetes deployment path, observability, LLM cost controls, and enterprise readiness, then turn that into a practical engineering roadmap.
You can also start with the broader AI Platform Engineering overview.
